I'd love to see a thorough breakdown of what these local NPUs can really do. I've had friends ask me about this (as the resident computer expert) and I really have no idea. Everything I see advertised for (blurring, speech to text, etc...) are all things that I never felt like my non-NPU machine struggled with. Is there a single remotely killer application for local client NPUs?
I used to work at Intel until recently. Pat Gelsinger (the prior CEO) had made one of the top goals for 2024 the marketing of the "AI PC".
Every quarter he would have an all company meeting, and people would get to post questions on a site, and they would pick the top voted questions to answer.
I posted mine: "We're well into the year, and I still don't know what an AI PC is and why anyone would want it instead of a CPU+GPU combo. What is an AI PC and why should I want it?" I then pointed out that if a tech guy like me, along with all the other Intel employees I spoke to, cannot answer the basic questions, why would anyone out there want one?
It was one of the top voted questions and got asked. He answered factually, but it still wasn't clear why anyone would want one.
Also professionals that need powerful computers ("workstations") in their jobs, like video editing
A lot of them are incorporating AI in their workflow, so making local AI better would be a plus. Unfortunately I don't see this happening unless GPUs come with more VRAM (and AI companies don't want that, and are willing to spend top dollar to hoard RAM)
Pretty much the same as what you see in the comments here. For certain workloads, NPU is faster than CPU by quite a bit, and I think he gave some detailed examples at the low level (what types of computations are faster, etc).
But nothing that translated to real world end user experience (other than things like live transcription). I recall I specifically asked "Will Stable Diffusion be much faster than a CPU?" in my question.
He did say that the vendors and Microsoft were trying to come up with "killer applications". In other words, "We'll build it, and others will figure out great ways to use it." On the one hand, this makes sense - end user applications are far from Intel's expertise, and it makes sense to delegate to others. But I got the sense Microsoft + OEMs were not good at this either.
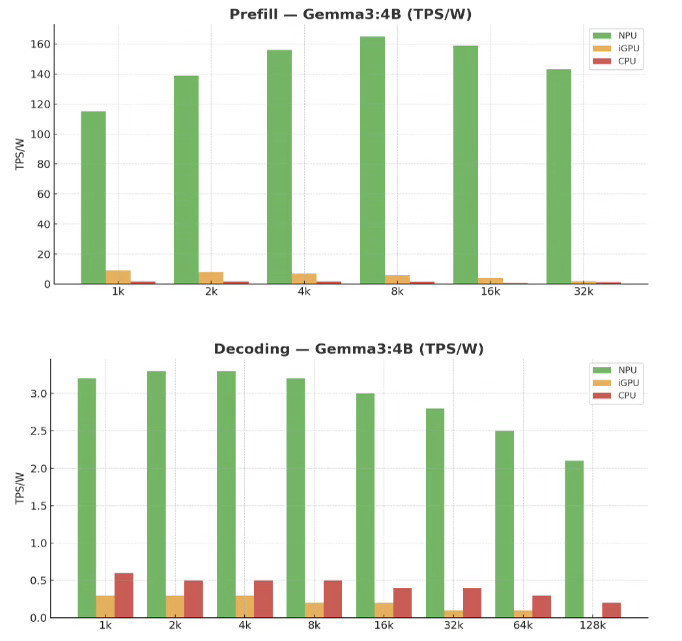
The problem is essentially memory bandiwdth afiak. Simplifying a lot in my reply, but most NPUs (all?) do not have faster memory bandwidth than the GPU. They were originally designed when ML models were megabytes not gigabytes. They have a small amount of very fast SRAM (4MB I want to say?). LLM models _do not_ fit into 4MB of SRAM :).
And LLM inference is heavily memory bandwidth bound (reading input tokens isn't though - so it _could_ be useful for this in theory, but usually on device prompts are very short).
So if you are memory bandwidth bound anyway and the NPU doesn't provide any speedup on that front, it's going to be no faster. But has loads of other gotchas so no real "SDK" format for them.
Note the idea isn't bad per se, it has real efficiencies when you do start getting compute bound (eg doing multiple parallel batches of inference at once), this is basically what TPUs do (but with far higher memory bandwidth).
NPUs are still useful for LLM pre-processing and other compute-bound tasks. They will waste memory bandwidth during LLM generation phase (even in the best-case scenario where they aren't physically bottlenecked on bandwidth to begin with, compared to the iGPU) since they generally have to read padded/dequantized data from main memory as they compute directly on that, as opposed to being able to unpack it in local registers like iGPUs can.
> usually on device prompts are very short
Sure, but that might change with better NPU support, making time-to-first-token quicker with larger prompts.
Yes I said that in my comment. Yes they might be useful for that - but when you start getting to prompts that are long enough to have any significant compute time you are going to need far more RAM than these devices have.
Obviously in the future this might change. But as we stand now dedicated silicon for _just_ LLM prefill doesn't make a lot of sense imo.
You don't need much on-device RAM for compute-bound tasks, though. You just shuffle the data in and out, trading a bit of latency for an overall gain on power efficiency which will help whenever your computation is ultimately limited by power and/or thermals.
The idea that tokenization is what they're for is absurd - you're talking a tenth of a thousandth of a millionth of a percent of efficiency gain in real world usage, if that, and only if someone bothers to implement it in software that actually gets used.
NPUs are racing stripes, nothing more. No killer features or utility, they probably just had stock and a good deal they could market and tap into the AI wave with.
Apple demonstrates this far better. I use their Photos app to manage my family pictures. I can search my images by visible text, by facial recognition, or by description (vector search). It automatically composes "memories" which are little thematic video slideshows. The FaceTime camera automatically keeps my head in frame, and does software panning and zooming as necessary. Automatic caption generation.
This is normal, standard, expected behavior, not blow your midn stuff. Everyone is used to having it. But where do you think the computation is happening? There's a reason that a few years back Apple pushed to deprecate older systems that didn't have the NPU.
I've yet to see any convincing benchmarks showing that NPUs are more efficient than normal GPUs (that don't ignore the possibility of downclocking the GPU to make it run slower but more efficient)
NPUs are more energy efficient. There is no doubt that a systolic array uses less watts per computation than a tensor operation on a GPU, for these kinds of natural fit applications.
Are they more performant? Hell no. But if you're going to do the calculation, and if you don't care about latency or throughput (e.g. batched processing of vector encodings), why not use the NPU?
Especially on mobile/edge consumer devices -- laptops or phones.
In theory NPUs are a cheap, efficient alternative to the GPU for getting good speeds out of larger neural nets. In practice they're rarely used because for simple tasks like blurring, speech to text, noise cancellation, etc you can get usually do it on the CPU just fine. For power users doing really hefty stuff they usually have a GPU anyway so that gets used because it's typically much faster. That's exactly what happens with my AMD AI Max 395+ board. I thought maybe the GPU and NPU could work in parallel but memory limitations mean that's often slower than just using the GPU alone. I think I read that their intended use case for the NPU is background tasks when the GPU is already loaded but that seems like a very niche use case.
If the NPU happens to use less power for any given amount of TOPS it's still a win since compute-heavy workloads are ultimately limited by power and thermals most often, especially on mobile hardware. That frees up headroom for the iGPU. You're right about memory limitations, but these are generally relevant for e.g. token generation not prefill.
> Everything I see advertised for (blurring, speech to text, etc...) are all things that I never felt like my non-NPU machine struggled with.
I don’t know how good these neural engines are, but transistors are dead-cheap nowadays. That makes adding specialized hardware a valuable option, even if it doesn’t speed up things but ‘only’ decreases latency or power usage.
I think a lot of it is just power savings on those features, since the dedicated silicon can be a lot more energy efficient even if it's not much more powerful.
NPUs really just accelerate low-precision matmuls. A lot of them are based on systolic arrays, which are like a configurable pipeline through which data is "pumped" rather than a general purpose CPU or GPU with random memory access. So they're a bit like the "synergistic" processors in the Cell, in the respect that they accelerate some operations really quickly, provided you feed them the right way with the CPU and even then they don't have the oomph that a good GPU will get you.
You definitely would use SIMD if you were doing this sort of thing on the CPU directly. The NPU is just a large dedicated construct for linear algebra. You wouldn't really want to deploy FPGAs to user devices for this purpose because that would mean paying the reconfigurability tax in terms of both power-draw and throughput.
Yes but your CPUs have energy inefficient things like caches and out of order execution that do not help with fixed workloads like matrix multiplication. AMD gives you 32 AI Engines in the space of 3 regular Ryzen cores with full cache, where each AI Engine is more powerful than a Ryzen core for matrix multiplication.
I thought SSE2 and everything that came after like AVX 512 or SSE4 were made for streaming, leveraging the cache only for direct access to speed things up?
Haven't used SSE instructions for anything other than fiddling around with it yet, so I don't know if I'm wrong in this assumption. I understand the lock state argument about cores due to always max 2 cores being able to access the same cache/memory... but doesn't this have to be identical for FPUs if we compare this with SIMD + AVX?
It’s more like you need to program a dataflow rather than a program with instructions or vliw type processors. They still have operations but for example I don’t think ethos has any branch operations.
There are specialized computation kernels compiled for NPUs. A high-level program (that uses ONNX or CoreML, for example) can decide whether to run the computation using CPU code, a GPU kernel, or an NPU kernel or maybe use multiple devices in parallel for different parts of the task, but the low-level code is compiled separately for each kind of hardware. So it's somewhat abstracted and automated by wrapper libraries but still up to the program ultimately.
ChatGPT has become an indispensable health tool for me. It serves as a great complement to my doctor. And there's been at least two cases in our house where it provided recommendations that were of great value (one possibly life saving and the other saving from an unnecessary surgery). I think that specialized LLMs will eventually be the front-line doctor/nurse.
Curious, does anyone know if this might also apply to tendons? I've had patella tendonitis for years (jumpers knee) and have tried everything (isometrics, shockwave, PRP injections, etc...).
Yep. Do those on a slant board. And knee extensions. And a few others. Plus drink collagen before it. I’m still working my way through it so it might work, but I’d love for something like this to work.
I didn’t plan on examining Elon’s ideology. He shoved it in my face. If other CEOs want to to be coy with Nazi salutes and post the types of things he does on X then let me know. I’ll happily treat them the same way.
Ironically, this might end up being more widely watched now (Streisand). I’ve seen multiple people on my Facebook link to different sources hosting the video. People who never would’ve heard about the story are now watching it through the lens of Trump and CBS trying to kill the story.
I doubt it, around ten million people watch 60 minutes live every week. Maybe that many will hear about the cancellation, but I don't think most will then seek out the full segment online, even if it's easy to find.
Yeah, even those looking for the full segment will have trouble finding it if they are not tech savvy and highly motivated.
A relative in their 60s saw headlines about the cancellation and wasn’t able to find it until I sent them the archive.org link. They are relatively well informed and competent with technology but never go around digging for hard to find media.
I think people on HN tend to overestimate how closely people follow news and how hard they are willing to work to seek out alternative sources of information. I’m with some extended family over the holidays. They might have seen this segment had it aired - I believe it was airing after some football game - but now there’s no chance of that happening. I don’t judge them for it at all, but most of their news consumption is passive through TV or social media. I think a lot of people follow news that way. Life’s busy.
It kind of makes me understand a little better how the censorship regime in other countries is so effective despite it being so easy to hop on a VPN. Raising the barrier to entry even a little reduces the audience from 10,000,000 to a fraction of that, even with the censorship itself being public knowledge.
You don’t hold a story because you want to push the government harder to respond, especially when you have the executive’s official spokesperson giving a reason on the record already.
And what does she mean that we should spend a beat explaining that half do have criminal histories? She wants them to give a cookie for that? And why is being charged relevant? You don’t send someone to prison for life for being charged.
Lastly she misstates the administrations legal justification for deportation. She doesn’t appear to be an unbiased actor here.
The fact she sent that out publicly is a good indication of how prejudiced she will be with editorial content.
> And why is being charged relevant? You don’t send someone to prison for life for being charged.
Yup. I was charged with a felony of which I was materially innocent.
But this is the right's spin on things, the "well even if you weren't found guilty, there was enough of an issue to arrest you and charge you".
I was watching a Zoom meeting of one of our local Superior Court hearings - was a motion to revoke or modify bail conditions.
The Judge actually rebuked the prosecutor, who had tried to explain why the motion should go their way. "Blah blah, in addition, the defendant has shown no signs of remorse or regret for the situation..."
Judge: "I'm going to stop you there. The defendant pled not guilty and at this moment no verdict has been determined. In the eyes of the law and this court, they have zero obligation or requirement to show remorse or regret for their alleged actions."
When i was growing up “correspondence chess” was a thing. Where you submitted your next move to your opponent over snail mail. Even back then I thought this was too slow for me, but I later understood that people would play many different game simultaneously.
It's still a thing and they even have world championships in it. Everyone always draws because it's basically just Stockfish vs. Stockfish. (Okay in the most recent one there were actually a shared first place, a shared second place, and one person in third place. The latter died during the tournament, and whether the others ended up in first or second place depended on whether they had drawn with third place before he died or if they won on time.)
I think you can view it as supply chain as the supply chain is about attacking resources used to infiltrate downstream (or is it upstream? I get which direction I should think this flows).
As an end user you can't really mitigate this as the attack happens in the supply chain (Mintlify) and by the time it gets to you it is basically opaque. It's like getting a signed malicious binary. It looks good to you and the trust model (the browser's origin model) seems to indicate all is fine (like the signing on the binary). But because earlier in the supply chain they made a mistake, you are now at risk. Its basically moving an XSS up a level into the "supply chain".
This makes use of a vulnerability in a dependency. If they had recommended, suggested, or pushed this purposefully vulnerable code to the dependency, then waited for a downstream (such as Discord) to pull the update and run the vulnerable code, then they would have completed a supply chain attack
The whole title is bait. Nobody would have heard of the dependency, so they don't even mention it, just call it "a supply chain" and drop four big other names that you have heard of to make it sexy. One of them was actually involved that I can tell from the post, that one is somewhat defensible. They might as well have written in the title that they've hacked the pentagon, if someone in there uses X and X had this vulnerable dependency, without X or the pentagon ever being contacted or involved or attacked
It does attack the supply chain. It attacks the provider of documentation. It's an attack on the documentation supply chain.
It would be like if you could provide a Windows Update link that went to Windows Update, but you could specify Windows Update to retrieve files from some other share that the malicious actor had control of. It's the same thing, except rather than it being a binary rather it is documentation.
{kind=link}
I also love Concrete Mathematics.
I prefer the Tanenbaum OS books over Stallings. In particular the design and implementation book, although it is more than a decade old now.
reply